Data Mining
Hidden within the vast mountains of data found in databases lies undiscovered knowledge that can scarcely be brought to light without appropriate tools. This is where Data Mining comes into play, providing methods and algorithms to uncover previously unknown relationships.
This book covers the material typically taught in a one-semester university-level course on Data Mining and is designed as a classic textbook.
Chapter 1 - Introduction
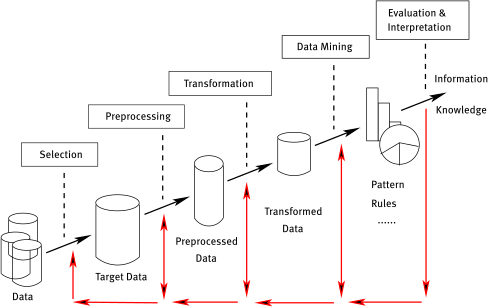
This chapter provides a general introduction to the field of Data Mining and explains some basic terms.
- What is Data Mining and what can it do?
- Structure of the book
- Data analysis process
- Interdisciplinarity
- Tools
Files
- [1] Weather data, numercal, [2] and nominal
- [3] Knime-Weather-Workflow Fig. 1.6 / 1.8 (you have to configure the FileReader)
- [4] Iris data, arff-Format
- [5] Knime-Loops Fig. 1.13 (you have to configure the FileReader)
Tools
- Knime: http://www.knime.org/
- WEKA: http://www.cs.waikato.ac.nz/ml/weka/
- JavaNNS
- Rapid Miner http://rapid-i.com
Competitions
Data collections:
- Kaggle: http://www.kaggle.com/
- Open Data Inception opendatainception.io
- Google Clud https://cloud.google.com/public-datasets/
- GitHub https://github.com/awesomedata/awesome-public-datasets
- Open Data on AWS https://registry.opendata.aws/
- EU Open Data Portal https://data.europa.eu/euodp/en/data/
- World-Bank https://data.worldbank.org/
- WHO https://www.who.int/gho/database/en/
- Data.gov https://catalog.data.gov/dataset
Here are some notes on the tasks in the book.
Chapter 2 - Fundamentals
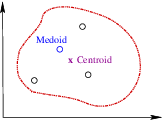
This chapter clarifies some fundamental concepts.
- Basic terms
- Data types
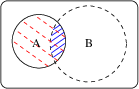
- Similarity/distance measures
- Fundamentals of artificial neural networks
- Logic
- Supervised and unsupervised learning
Chapter 3 - Application classes
This chapter provides an overview of the application classes in Data Mining.
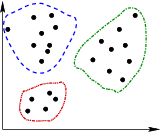
- Cluster analysis
- Classification
- Numerical prediction
- Association analysis
- Text mining
- Web mining
Chapter 4 - Knowlede Representation
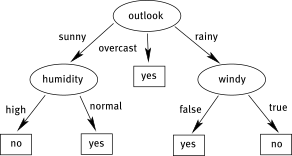
This chapter provides an overview of the possibilities for representing (Data Mining) knowledge on a computer.
- Decision table
- Decision trees
- Rules
- Association rules
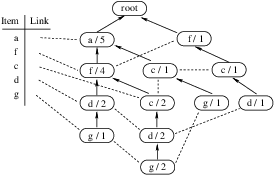
- Instance-based representation
- Representation of clusters
- Neural networks as knowledge repository
Chapter 5 - Classification
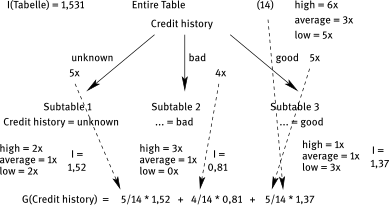
This chapter provides an overview of basic classification methods.
- k-Nearest Neighbour
- Decision Trees
- Naive Bayes
- Feed-forward Neural Networks
- SVM
Files
- [1] Income data
- [2] Knime-KNN-Income (you have to reconfigure the FileReader)
- Weather data (nominal, csv). Training set [3] und Test set [3a].
- [4] Knime-NaiveBayes-Weather (you have to reconfigure the FileReader)
- [5] Employee data (csv)
- [6] Knime-SVM Employee data (you have to reconfigure the FileReader)
Chapter 7 - Association analysis
This chapter provides an overview of basic association analysis methods.
- A-Priori
- Frequent Pattern Growth
Files
- [1] Condition data, csv-Format (Tab. 7.1)
- Link auf die Umfrage 2006 (available only in German)
Chapter 8 - Data Preparation
This chapter provides an overview of basic data preparation techniques.
- Data selection and integration
- Data cleansing
- Data reduction
- Data transformation
Files
Chapter 10 - Example
This chapter discusses possible approaches to the Data Mining Cup 2002.
Best score in the DM Cup 2002 :
- 12.12.13 Tanja Ciernioch (Wismar University of Applied Sciences): 7,771.80
Dateien
- The DMC Task 2002.
- [2]Knime-Workflow first attempt (Fig. 10.1).
- [3]Knime-Workflow k-nearest neighbor (Fig. 10.5).
- [4]Knime-Workflow Naive Bayes (Fig. 10.6).
- [5]Knime-Workflow Decision Tree 1 (Fig. 10.7).
- [6]Knime-Workflow Decision Tree 2 (Fig. 10.8).
- [7]Knime-Workflow Neural Network (Fig. 10.9).